


















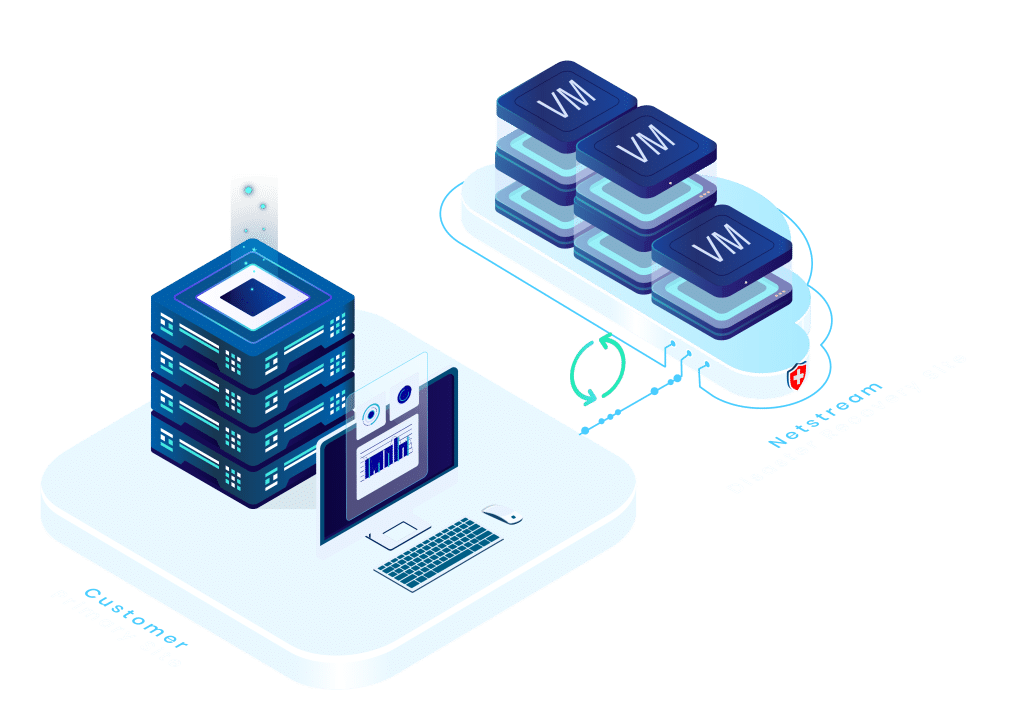
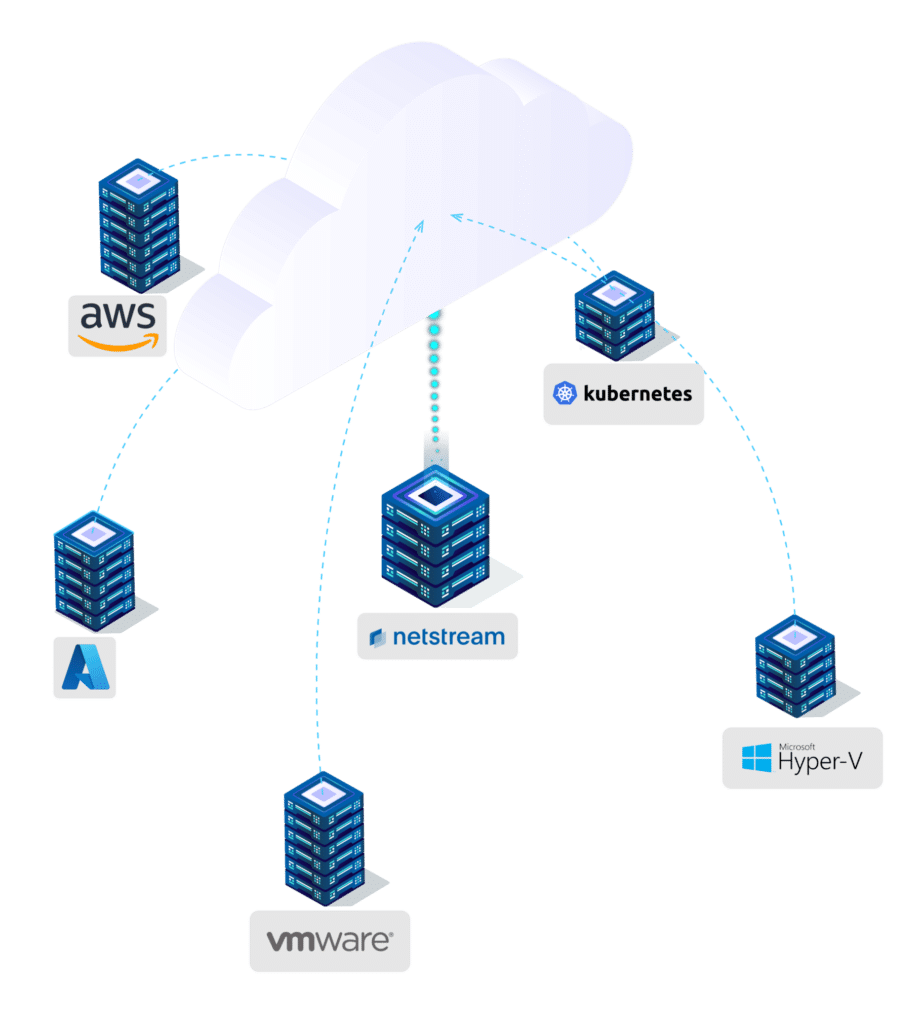

Platform-independent cold Migration the Cloud
The reasons for Migration the Cloud : rising operating costs, new security requirements, or greater flexibility. A predictable, controlled migration is crucial, especially for complex system landscapes. Anyone who wants to migrate systems...
Migration scenario without interruption of operations
Many companies start with data backup and shortly thereafter begin operating their systems productively in the Cloud. This Migration a controlled, secure, and effortless step-by-step Migration . The...

Assessing criticality: The basis for yourRecovery
Evaluate the criticality of your IT systems in a standardized way instead of using gut feeling. We will show you a simple and proven method that will prevent you from failing your assessment. If...

VMware license change 2025: Broadcom increases minimum requirements
Since the takeover of VMware by Broadcom, one change has followed the next. Many companies are not very happy about this. Smaller IT environments and service providers in particular...

Hybrid financing models for the Cloud: CAPEX vs. OPEX
In the dynamic world of IT, companies are faced with the challenge of efficiently financing their Cloud. Traditionally, they have opted for on-prem infrastructure for CAPEX (investment costs) and for...

Human error as a cause of IT disruptions
Hardware failures, problems with the software or ransomware are well-known causes of disruptions and failures in IT. But human errors are also an unavoidable part of IT departments and are...

High availability for business critical databases
Hardly any company can do without databases these days. A disaster or a logical error that affects the availability of the database can lead to data loss, reduce the productivity of the...

How to create a Disaster Recovery plan (DRP)
A Disaster Recovery Plan (DRP) is a critical process for any business or organization to ensure that in the event of an outage or disruption to IT infrastructure or other business-critical assets, the business can...