


















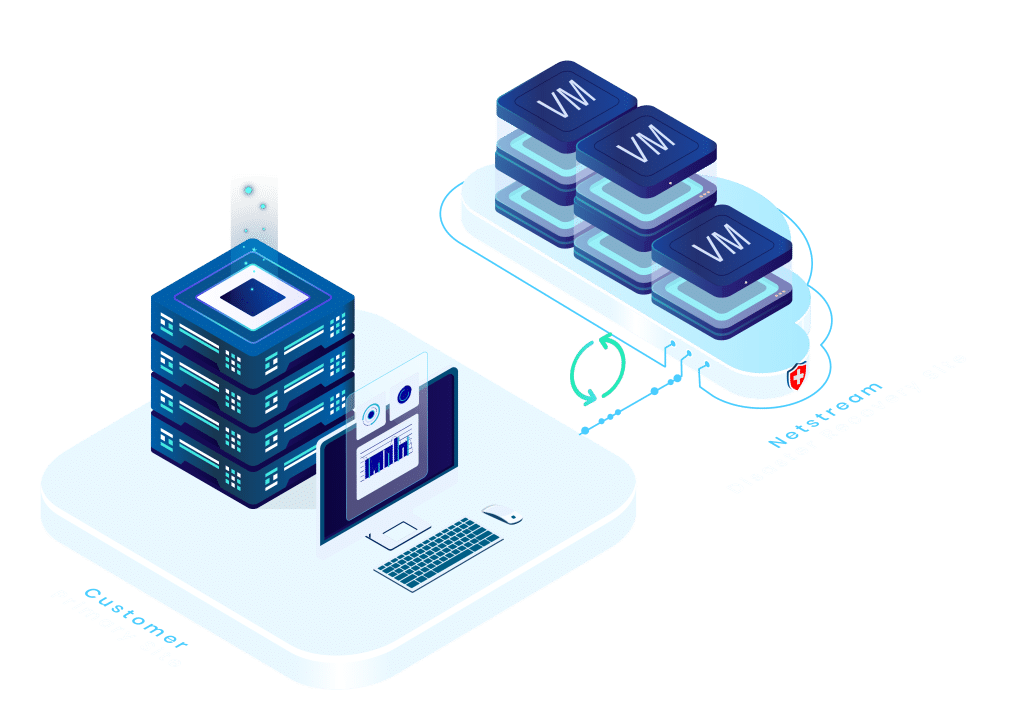
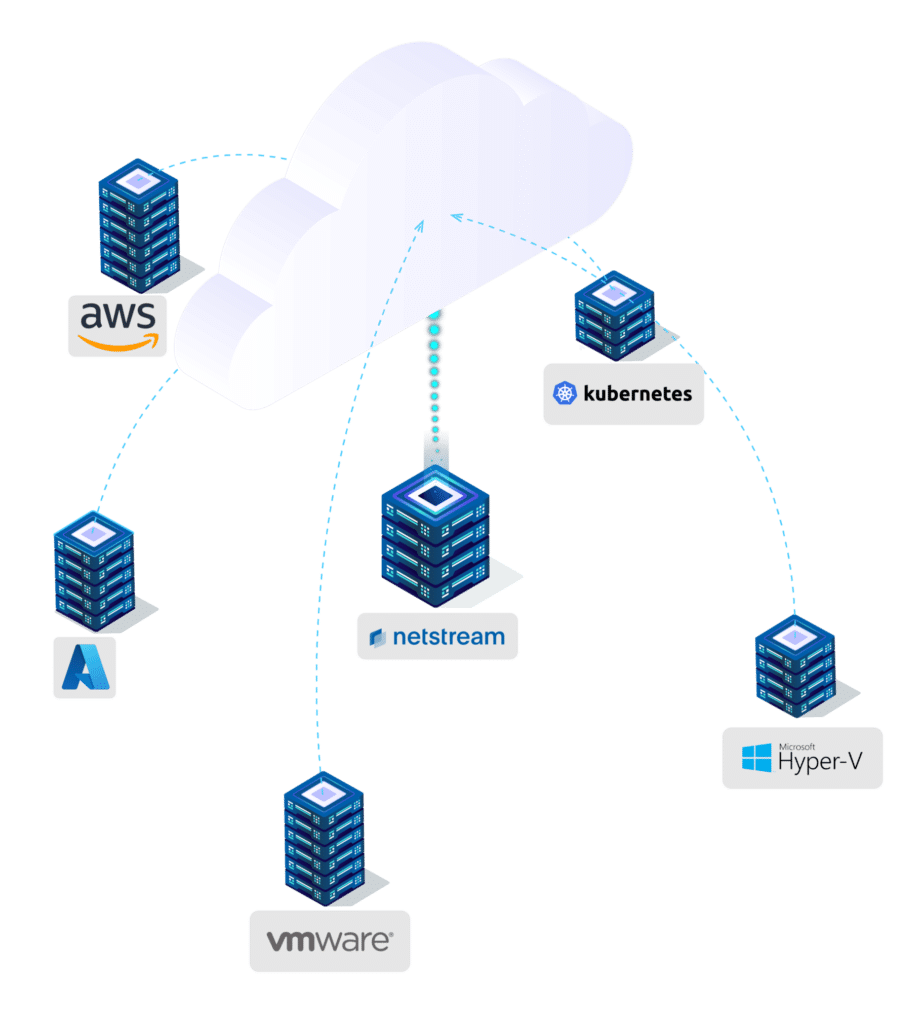

Migration à froid Migration le Cloud, indépendamment de la plateforme
Les raisons d'une Migration le Cloud diverses : augmentation des coûts d'exploitation, nouvelles exigences en matière de sécurité ou plus grande flexibilité. Un transfert planifiable et contrôlé est particulièrement important dans le cas d'environnements système complexes. Ceux qui utilisent des systèmes...
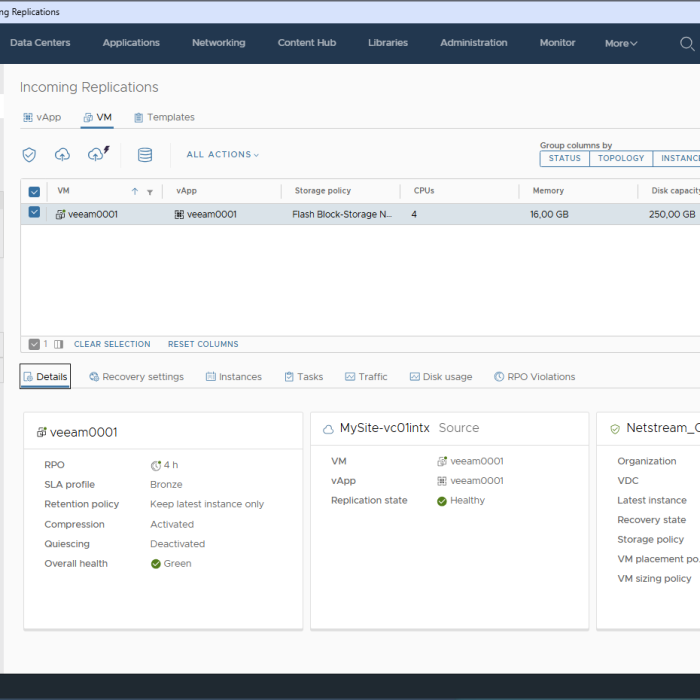
Scénario de migration sans interruption de service
De nombreuses entreprises commencent par sauvegarder leurs données, puis exploitent rapidement leurs systèmes dans le Cloud. La Migration progressive Migration ainsi de manière contrôlée, sécurisée et sans effort inutile. La...

Évaluer la criticité : la base de votreRecovery
Évaluez la criticité de vos systèmes informatiques de manière uniforme, plutôt qu'à l'instinct. Nous vous présentons une méthode à la fois simple et éprouvée qui vous permettra de ne plus échouer lors de l'évaluation. Si...

Modification de la licence VMware 2025 : Broadcom augmente les exigences minimales
Depuis le rachat de VMware par Broadcom, les changements s'enchaînent. Pour de nombreuses entreprises, la joie est limitée. En particulier les petits environnements informatiques et les prestataires de services...

Modèles de financement hybrides pour le Cloud: CAPEX vs. OPEX
Dans le monde dynamique de l'informatique, les entreprises sont confrontées au défi de financer efficacement leurs Cloud. Traditionnellement, elles ont opté pour l'infrastructure sur site pour les CAPEX (coûts d'investissement) et pour...

L'erreur humaine comme cause des perturbations informatiques
Les pannes matérielles, les problèmes avec les logiciels ou les ransomwares sont des causes connues de perturbations et de pannes dans l'informatique. Mais les erreurs humaines font aussi partie intégrante des services informatiques et sont...

Haute disponibilité pour les bases de données critiques
De nos jours, rares sont les entreprises qui peuvent se passer de bases de données. Une catastrophe ou une erreur logique affectant la disponibilité de la base de données peut entraîner des pertes de données, réduire la productivité des...

Pour créer un planRecovery (PRA)
Un plan deRecovery (PRA) est un processus critique pour toute entreprise ou organisation afin de garantir la continuité de l'activité en cas de panne ou de dysfonctionnement de l'infrastructure informatique ou d'autres...